作者: 兆光科技 发布时间: 2025/04/17 点击: 1002次
进入2023年后,或许已经鲜少有网友还没听过ChatGPT这个大名。这一继元宇宙之后出现的“新浪潮”,俨然已经成为了今年科技圈的风口,包括海外市场的微软、谷歌、亚马逊,以及国内的百度、阿里、腾讯、字节跳动在内,几乎但凡有一定技术实力的科技厂商也悉数下场,即便是技术力不够的厂商也是八仙过海各显神通,有诸如知乎这样联手合作伙伴的,也有像“美国贴吧”Reddit这样“卖资源”的。
日前Reddit方面宣布,将开始对使用其应用程序编程接口(API)的企业收费,该接口则提供了下载和处理人与人之间对话的相关数据。事实上,Reddit的API自2008年以来就一直是以免费的方式开放给第三方,对于突然转向收费,Reddit方面的解释,是此举为了限制其API被用于训练人工智能工具,其中包括OpenAI的ChatGPT、谷歌的Bard,以及微软的Bing AI等。
尽管Reddit暂时还没有公布其API的具体收费标准,但官方已经透露,将为“需要额外功能、更高使用限制和更广泛使用权的第三方,引入一个新的高级接入点”。而为了避免被外界指责“吃相难看”,Reddit方面还表示将会对一些访问API的用户免费,而这类用户则主要包括科研机构的研究人员,或是从事非商业目的的研究员。
Reddit为何敢于去收这笔钱呢?其实成立于2005年的Reddit,已经是全球互联网中历史最悠久、同时也最有活力的社区之一。截止2021年10月,也就是Reddit官方最后一次披露的用户数据表明,其拥有5300万DAU和超过4.3亿MAU。而来自Statista的数据显示,Reddit是全美访问量第六大的社交媒体,月活水平与Instagram、Twitter几乎持平。
如此海量的用户也造就了Reddit的活跃社区总数超过了14万个,帖子总量超过3.66亿,评论总数为23亿,这也代表着沉淀在Reddit的内容已然成为了一个极为惊人的语料库。而在AI领域,语料(Corpus)通常是一定数量和规模的文本资源集合,作为一个以论坛为形式展开业务的平台,Reddit显然是当下英语互联网中最潮流、最日新月异的语料库。例如OpenAI开发的ChatGPT以及最新的GPT-4,就有很多训练数据被证实是来源于Reddit。
就像数据之于算法一样,语料则是ChatGPT这类生成式AI更加智慧的基础所在。生成式AI的原理,大概可以总结为通过大量的语料库进行训练,以建立相应的模型,从而使得AI能够对人类的问题作出相应的回答和决策,其核心逻辑就是“猜谜游戏”。经过大量的训练后,AI预测出问题的答案,并不等于拥有智慧,而只是在玩文字游戏,进行一次又一次的概率解谜,本质上与人类玩数独或填字游戏是一样的。
那么ChatGPT为什么会表现得比以往的人工智能产品、比如Siri更聪明呢?其实单纯是因为语料规模更大。例如GPT-3就拥有的1750亿的参数量、45TB的训练数据,以及高达1200万美元的训练费用,这也是OpenAI打造ChatGPT的基础。而ChatGPT聪明的关键就在于涌现能力(Emergent ability)上,指的是在不进行参数更新的情况下,只在输入中加入几个示例,就能让模型进行学习。
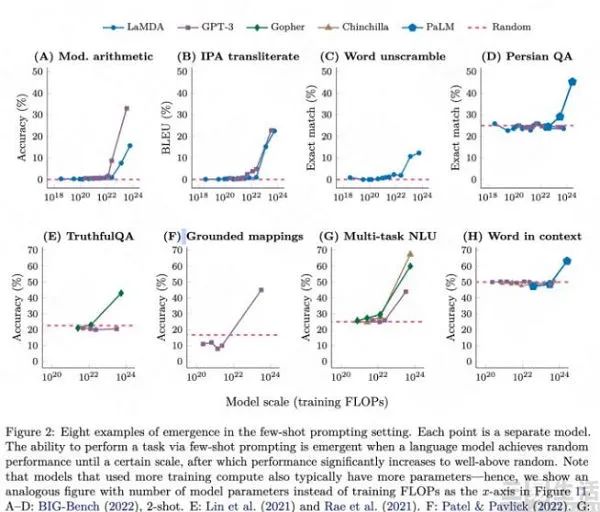
涌现能力从何而来呢,根据Google&Deepmind联合发布的相关论文显示,模型在没有达到一定规模前,得到的表现较为随机,但在突破规模的临界点后,表现则会大幅度提升。
例如在BIG-Bench上,GPT-3和LaMDA在未达到临界点时,模型的表现都是接近于零。而在GPT-3的规模突破2 · 10^22 training FLOPs (13B参数),LaMDA的规模突破10^23 training FLOPs (68B参数)后,表现就开始快速上升。
“力大砖飞”就是当下大语言模型的底层逻辑,在这种情况下,语料基本决定了大语言模型的上限。语料虽然是越多越好,但问题是已经没有更多高质量的数据供模型进行训练了。
AI研究团队Epoch在今年年初发表的论文表明,AI不出5年就会把人类所有的高质量语料用光。而且这一结果,则是Epoch将人类语言数据增长率,即全体人类未来5年内出版的书籍、撰稿的论文、编写的代码,都考虑在内预测出的结果。
Epoch团队将语料分为了高质量和低质量两种,其中高质量的语料指的是包括维基百科、新闻网站、GitHub上的代码、出版书籍等,低质量语料则来源于Twitter、Facebook,以及Reddit上的内容。
正常情况下,AI厂商自然更愿意使用高质量的语料,毕竟这能够在最大限度上避免被偏见和歧视性言论“污染”。但问题是,据统计,高质量语料数据的存量只剩下约4.6×10^12~1.7×10^13个单词,相比当前最大的文本数据集大了不到一个数量级。
所以当高质量语料不够用的情况下,低质量语料即便再不好用也得用,不然大语言模型要如何成长。而对于低质量语料,充其量也只是在数据标注和清洗上投入更多成本,所以OpenAI、谷歌、亚马逊等公司相当于就没得选。所以Reddit如今就正是挟语料自重,料定了AI厂商只能硬着头皮买。
标签: ChatGPT
版权申明:本站文章部分自网络,如有侵权,请联系:hezuo@lyzg168.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有
输入您的联系信息,我们将尽快和你取得联系!
Tel:18623768730
企业QQ:210603461
Emile:hezuo@lyzg168.com
地址:洛阳市西工区王城大道221号富雅东方B座1711室
网站:https://www.lyzg168.com

我们的微信
关注兆光,了解我们的服务与最新资讯。
Copyright © 2018-2019 洛阳兆光网络科技有限公司
 豫公网安备41030302000813号
豫ICP备18025879号
豫公网安备41030302000813号
豫ICP备18025879号